How my link blog works
Despite not posting stuff as much as I’d like to get around to on this site, I do keep my link blog pretty active. It lets me share publicly some links to things on the web, sometimes with commentary.
I run the Hugo content management system, but the generalities could apply to a lot of systems if this is something that you’d like to replicate.
Here’s an overview of how I use it and how it works. The moving parts are:
- Saving links while browsing
- Bringing content into Hugo
- Displaying content in Hugo
- Creating an RSS feed
Saving links
While I’ve technically got content currently from four places — Pinboard (my account is private by default on that site), GitHub starred repositories, and Thingiverse and Cults likes of 3D printed designs, only the first two are really active, so I’ll focus on those as examples in case they might serve as inspiration for your own sort of system.
I’ll start with GitHub. All I do is press the star button on a repository. Easy. Something I was doing already anyway.

For Pinboard, I use one of the bookmarklets, which is way of using a bit of JavaScript code as a browser bookmark that, when visited, will capture information about the current page and turn it around into a Pinboard posting popup window.

The bookmarklet code:
javascript:q=location.href;if(document.getSelection){d=document.getSelection();}else{d='';};p=document.title;void(open('https://pinboard.in/add?url='+encodeURIComponent(q)+'&description='+encodeURIComponent(d)+'&title='+encodeURIComponent(p),'Pinboard','toolbar=no,width=700,height=350'));
In order to streamline this, I made a Safari-specific keyboard shortcut, ⌘B (hat tip to this StackExchange post for info on producing the ⌘ symbol).
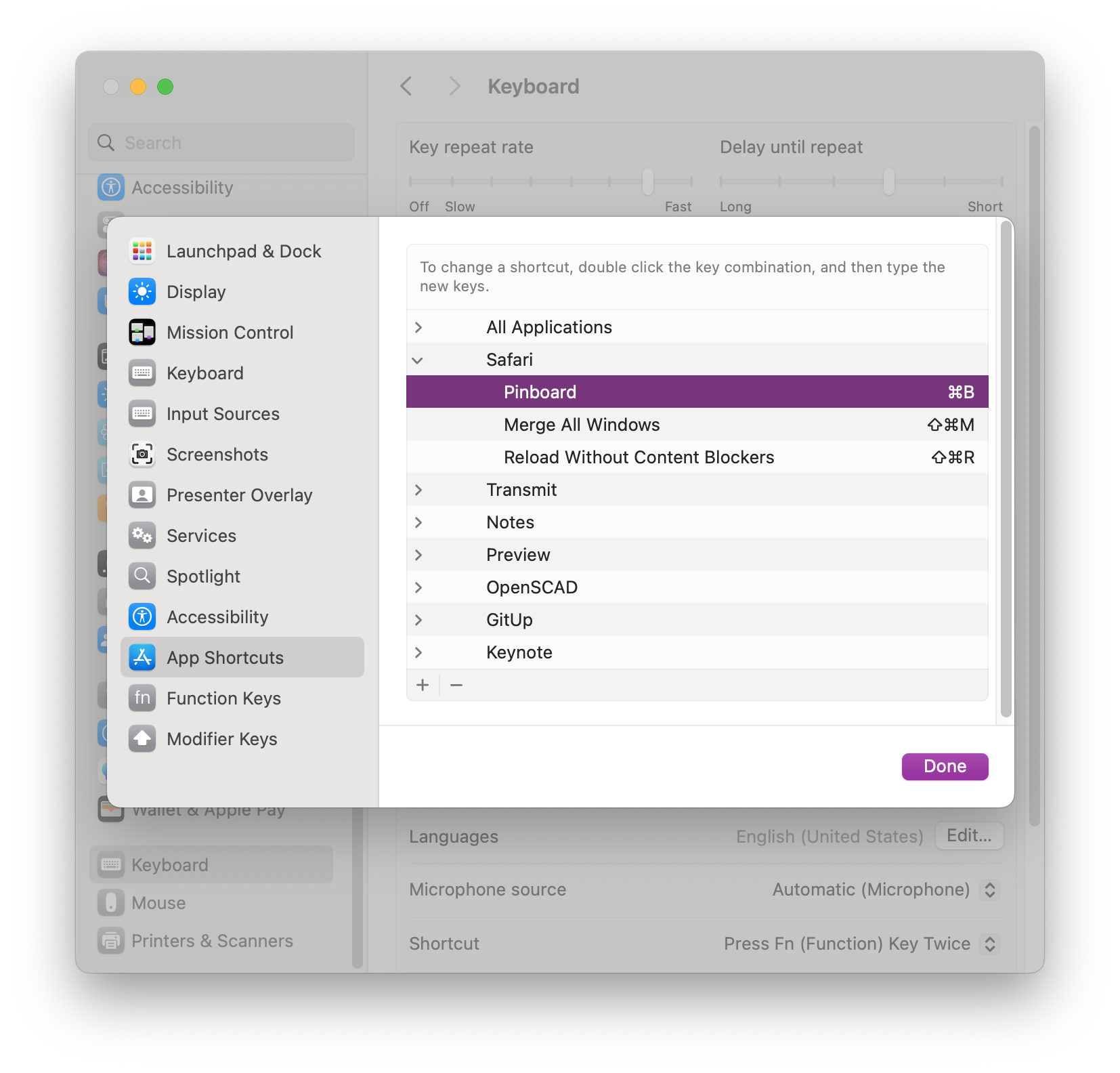
This works because you can setup keyboard shortcuts system-wide in any app by menu item name and I’ve appropriately named the bookmarklet, which shows up in Safari’s Bookmarks menu, even though I never use it there. Just having it buried somewhere in the Mac menu system for Safari is enough for the shortcut to be able to access it.
For Pinboard, there’s also a page of posting clients, so you do you. I actually used to work on my own Mac-native posting client, Pukka, but it is, alas, no more. It was part of what got me interested in Pinboard in the first place.
When posting a link to Pinboard, there are five things that I do specifically for my system.
- I might highlight some page content before using the bookmarklet, which gets transferred into the description field as a starting point (
document.getSelection()takes care of this above). - I remove any tracking or other query string crap from the URL so that it is clean for the next person.
- I edit out the oft-added site name at the end of the page title.
- Alongside my normal tags, I add a special tag (
links) if it’s something that I want to show up on this site. - Optionally, I add or edit the commentary, possibly with quoting (using Markdown’s
>).

I use Markdown in the description since this will eventually get piped through to my site and rendered by Hugo. I like sparing use of italics (_foo_) or bold (**bar**) and sometimes bullet lists (- baz).
With both GitHub and Pinboard, I can bookmark while I’m browsing, not have to think about it very much, and move on.
Bringing content into Hugo
The next part of the system is something that I’ll either do manually on a fairly regular basis or as part of my deployment of other new content (like this post) on the site.
Basically, for each link source, I’ve written a Python script to use its API to download content. There is a lot of potential for reuse between them still, and I’m not proud of the code, but it’s for me and it works. I’d consider releasing them, but this does not come without the possibility of support. I’d rather this post serve as an inspiration for similar systems.
For GitHub, I use their stars endpoint, which doesn’t even require authentication, since this is public data.
USERNAME = 'incanus'
STORE = './data/links/github_stars.json'
PER_PAGE = 100
URL = f"https://api.github.com/users/{USERNAME}/starred?per_page={PER_PAGE}"
HEADERS = {
'Accept': 'application/vnd.github.v3.star+json'
}
The paging allows my script to compare results with what it has on disk and only grab recent pages of results as needed.
After some munging, I store things into the JSON file in the sort of place where Hugo likes data.
For Pinboard, I use my account username and password and their API.
STORE = './data/links/pinboard_public.json'
TAG = 'links'
PER_PAGE = 100
URL = f"https://{USERNAME}:{PASSWORD}@" \
f"api.pinboard.in/v1/posts/recent" \
f"?tag={TAG}&format=json&count={PER_PAGE}"`
Similar sort of thing here — munge the various fields in the JSON received from Pinboard into a common format for Hugo in its JSON on disk.
Displaying content in Hugo
I feel like Hugo’s page on data templates does a pretty good job of explaining how it works. In my case, an individual entry in a link data file (regardless of source) looks something like this:
{
"name": "The Un-Brie-Lievable History of Tyromancy",
"description": "> Predicting the future using cheese is something I do as a side business, and from what I can tell, there aren\u2019t very many of us doing this anymore.",
"url": "https://www.saveur.com/culture/tyromancy-cheese-divination/",
"date": "2024-01-11T19:07:39Z",
"kind": "pinboard_public"
}
One thing that I don’t bring through is my Pinboard tags, since sometimes these refer to private projects or I otherwise don’t want to post what I’m tagging things under.
And it’s the kind field that I use to distinguish in my rendering code how things are displayed.
An entry on the links page looks something like this:

I like a terse version of the domain right after the title, and at the bottom, a permalink and bookmark date.
For GitHub stars, I pull the repository description if it exists so that things look like this:

Here’s what’s in my layouts/section/links.html to accomplish this, broken down a little.
First, start off the page by pulling a parameter from my config.yaml related to how many links I want to show per page.
<div class="posts">
{{ range (.Paginate .Site.Params.Counts.LinksPage).Pages.ByDate.Reverse -}}
Then, output the title linking to the URL and munge the link domain a bit to clean it up.
<article class="post">
<h2 class="post-title"><a href="{{ .Params.target }}">{{ .Title }}</a></h2>
{{- $domain := (urls.Parse .Params.target).Host | replaceRE "^www." ""}}
<p style="font-size: 0.75em; color: gray;">{{ $domain }}</p>
For the main body of the entry, depending on what type of link it is, I’ll do some processing.
- For GitHub stars, fill in a default description (since a lot of repos don’t have one) and display that description as if it were quoted content.
- For Thingiverse or Cults likes, include a thumbnail image of the model.
{{ $desc := .Content }}
{{- $desc := (cond (eq (chomp $desc) "") "_no description_" $desc) -}}
{{- $desc := (cond (eq .Params.kind "github_star") (printf "> %s" $desc) $desc) -}}
{{- $desc := (cond (or (eq .Params.kind "thingiverse_like") (eq .Params.kind "cults_like")) (delimit (slice "<a href=\"" .Params.target "\"><img src=\"" .Params.thumbnail "\" style=\"width: 350px; margin: 20px 0px 25px 0px; box-shadow: 5px 5px 10px lightgray;\"/></a>") "") $desc) -}}
Here’s what a Thingiverse entry looks like.

In all cases, I run the resulting description through a few Hugo filters to render it safely.
<p>{{ $desc | markdownify | emojify | safeHTML }}</p>
Lastly, I add the permalink and date and close out the entry.
<a href="{{ .Permalink }}"><time datetime="{{ .Date.Local.Format "2006-01-02T15:04:05" }}" class="post-date">🔗 {{ .Date.Local.Format "Mon, Jan 2, 2006 at 3:04pm" }}</time></a>
</article>
{{- end }}
</div>
Individual link pages (something I added fairly recently, after a few years with this system) are more or less the same, just in layouts/links/single.html instead.
The link pages themselves have permalinks, so that each link that I’ve put on my site has a permanent page on which to live, allowing anyone else to link to that if they like. Is anyone doing that? I don’t know. I’d just like to give them the option. At the very least, it lets me link to my link-of-a-link, in case I want to pass my version (and commentary) of the link to someone else. And most importantly, I have my own links backed up, locally, in my website code. Combined with a paid Pinboard account’s archival service, this is a pretty good personal copy of my stuff.
The permalinks and the pages they link to get generated by a little links.py that I run. They look like this:
---
title: "jstasiak/python-zeroconf"
date: 2020-05-02T19:38:41
target: https://github.com/jstasiak/python-zeroconf
kind: github_star
---
A pure python implementation of multicast DNS service discovery
This file, as an example, lives forever at content/links/07bsoxfTSm.md.
The one thing that took some puzzling here (most of it is mungy-munge on the data JSON into the Markdown file) is the unique URL string (07bsoxfTSm above). I landed on the Sqids library for this, using it like so:
sq = Sqids(min_length=10)
[...]
for kind in kinds.keys():
l = run('ls content/links/*.md', shell=True, capture_output=True)
l = l.stdout.decode('utf-8').split('\n')
with open(f'data/links/{kind}.json', 'r') as f:
schema = kinds[kind]
j = json.load(f)
for b in j[schema['container']]:
d1 = int(datetime.fromisoformat(b['date'][0:-1]).timestamp())
d2 = len(b[schema['metadata']] or '')
h = sq.encode([d1, d2])
if not f'content/links/{h}.md' in l:
[...]
The script will, for each kind of link, compare the data file with the existing links files on disk in content/links to see if any links need a page generated for them. They then spit out the above content stub pages for Hugo to pickup and render according to the layouts/links/single.html template.
The Sqids-generated ID is based on a combination of the bookmark date (d1) and the “metadata” of the bookmark (d2) which is either the description text or, for the thumbnail links, the thumbnail URL. I’ve got to commit to a certain description before publishing the final version if I don’t want the “permalink” to change.
I realize that I am skipping a lot of functionality here, as well as assuming a large amount of familiarity with Hugo and its usage. Again, I hope this gives you some ideas on a way (not the best way! not necessarily the way for your site!) that you could accomplish such a thing.
This is very much a hacker’s way of jamming things together to just barely work, but it does the job for me. I’m fully aware that this is not for the average writer on their site. And it saddens me quite a bit to consider that in the past 15 or 20 years, instead of bringing this sort of functionality to everyone, instead we have giant data silos like Facebook or unprogrammable-but-nice site management solutions like Squarespace. The best I can hope for right now is to maybe show other hackers how I did this. I like sharing (and reading!) glimpses of others’ techniques as much as I like reading everything else on the web.
Creating an RSS feed
Speaking of nerds, the last bit of this system is an RSS feed. At this point, you’d probably not be surprised (or you know already) that Hugo makes RSS feeds quite easy.
There is a page stub at content/pages/links.xml.md that puts the feed in the right place.
---
layout: links
title: Links
url: /links.xml
outputs:
- rss
---
And there is a layout template at layouts/pages/links.xml that builds up the feed XML.
{{- printf "<?xml version=\"1.0\" encoding=\"utf-8\" standalone=\"yes\"?>" | safeHTML }}
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">
<channel>
<title>{{ .Site.Params.Author }} - Links</title>
<description>{{ .Site.Params.Description }}</description>
<link>{{ ref . "links.md" }}</link>
[...]
This is perhaps the most concise example of how Hugo combines content files and layout files in order to create the final rendered pages. Sometimes the content is in the actual page, but oftentimes, like this, it’s all in the layout (combined with data files) instead.
Once again we’re looping through the site content, with LinksFeed as the item count so that it can potentially be different than the HTML version.
{{- range first .Site.Params.Counts.LinksFeed (where .Site.RegularPages "Section" "=" "links").ByDate.Reverse }}
And an individual link RSS entry looks like this.
<item>
<title>{{ .Title }}</title>
<description>
{{- $domain := (urls.Parse .Params.target).Host | replaceRE "^www." "" -}}
<p><code>{{ $domain }}</code></p>
{{- $desc := .Content -}}
{{- $desc := (cond (eq $desc nil) "_no description_" $desc) -}}
{{- $desc := (cond (eq .Params.kind "github_star") (printf "> %s" $desc) $desc) -}}
{{- $desc := (cond (eq .Params.kind "thingiverse_like") (delimit (slice "<a href=\"" .Params.target "\"><img src=\"" .Params.thumbnail "\" style=\"width: 350px;\"/></a>") "") $desc) -}}
{{- $desc | markdownify | emojify | html -}}
<p><a href="{{ .Permalink }}">🔗</a></p>
</description>
<pubDate>{{ .Date.Format "Mon, 02 Jan 2006 15:04:05 -0700" | safeHTML }}</pubDate>
<link>{{ .Permalink }}</link>
<guid isPermaLink="true">{{ .Params.target }}</guid>
</item>
A lot of this is a variation on the HTML version, so I won’t cover much of it. I just wanted to show some of the RSS/XML-specific tweaks needed to make this all work.
Wrapping up
I do feel like I moved through this rather quickly (and it’s still long!) and again, it is admittedly Hugo-specific in its code content. I hope that it can be useful, though, to see how to build up such a system, as well as to highlight the fact that it takes an experienced programmer and somewhat half-assed blog author at least a dozen programming languages and/or data formats to put something like this together 30+ years into the web. I guess I started out enthusiastic about sharing some useful technical bits, and ended up rather pensive about an end result that I feel should be available to more people.
However, I think that this shows another good reason to blog, which is to actually take a moment to reflect on it all and assess the state of things. In that vein, I’d be curious to hear what other folks think about this or what they use for similar systems.